Week 0 Scratch 😺
resource
CS50 2019 - Lecture 0 - Computational Thinking, Scratch - YouTube
Lecture 0 - CS50x
Problem Set 0 - CS50x
CS50 Programmer’s Manual
What is computer science?
Computer science is fundamentally problem-solving.
Binary
- A computer, at the lowest level, stores data in binary, a numeral system in which there are just two digits,
0and1. - binary makes sense for computers because we power them with electricity, which can be either on or off, so each bit only needs to be on or off. In a computer, there are millions or billions of switches called transistors that can store electricity and represent a bit by being 『on』 or 『off』.
- 8 bits make up one byte.
Representing data
- To represent letters, all we need to do is decide how numbers map to letters.
- An image, too, is comprised of many smaller square dots, or pixels, each of which can be represented in binary with a system called RGB, with values for red, green, and blue light in each pixel.
- And videos are just many, many images displayed one after another, at some number of frames per second. Music, too, can be represented by the notes being played, their duration, and their volume.
Algorithms
- step-by-step instructions for solving a problem:
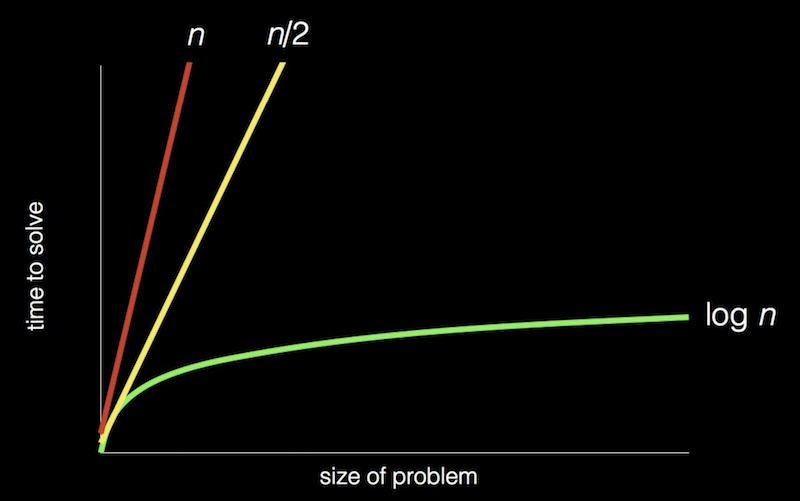
- In fact, we can represent the efficiency of each of those algorithms with a chart:
Pseudocode
Scratch
- We can write programs with the building blocks we just discovered:
- functions
- conditions
- Boolean expressions
- loops
- variables
- the ability to store values and change them
- threads
- the ability for our program to do multiple things at once
- events
- the ability to respond to changes in our program or inputs
Week 1 C
resource
CS50 2019 - Lecture 1 - C - YouTube
C
C: a programming language that has all the features of Scratch and more, but perhaps a little less friendly since it’s purely in text:
1 |
|
hello, world
In C, the function to print something to the screen is printf, where f stands for 『format』, meaning we can format the printed string in different ways.
To make our program work, we also need another line at the top, a header line #include <stdio.h> that defines the printf function that we want to use. Somewhere there is a file on our computer, stdio.h, that includes the code that allows us to access the printf function, and the #include line tells the computer to include that file with our program.
Compilers
Once we save the code that we wrote, which is called source code, we need to convert it to machine code, binary instructions that the computer understands directly.
We use a program called a compiler to compile our source code into machine code.
To do this, we use the Terminal panel:
- We type
clang hello.c(whereclangstands for 『C languages』, a compiler written by a group of people) - we can type
./a.outin the terminal prompt to run the programa.outin our current folder.
String
We can update our code to include a special newline character, \n:
1 |
|
- We can pass command-line arguments, or additional options, to programs in the terminal, depending on what the program is written to understand. For example, we can type
clang -o hello hello.c, and-o hellois telling the program clang to save the compiled output as justhello. Then, we can just run./hello.
In our command prompt, we can run other commands, like ls (list), which shows the files in our current folder:
1 | $ ls |
- The asterisk,
*, indicates that those files are executable, or that they can be run by our computer.
Now, let’s try to get input from the user
1 |
|
We can just type make string. We see that, by default in the CS50 Sandbox, make uses clang to compile our code from string.c into string, with all the necessary arguments, or flags, passed in.
compare string
We can’t compare strings directly, since they’re not a simple data type but rather an array of many characters, and we need to compare them differently. Luckily, the string library has a strcmp function which compares strings for us and returns 0 if they’re the same, so we can use that.
Scratch blocks in C
A condition would map to:
1 | if (x < y) |
We can also have if-else conditions:
1 | if (x < y) |
And even else if:
1 | if (x < y) |
Loops can be written like the following:
1 | while (true) |
We could do something a certain number of times with while:
1 | int i = 0; |
To do the same repetition, more commonly we can use the for keyword:
1 | for (int i = 0; i < 50; i++) |
Types, formats, operators
There are other types we can use for our variables
bool, a Boolean expression of eithertrueorfalsechar, a single character likeaor2double, a floating-point value with even more digitsfloat, a floating-point value, or real number with a decimal valueint, integers up to a certain size, or number of bitslong, integers with more bits, so they can count higherstring, a string of characters
And the CS50 library has corresponding functions to get input of various types:
get_charget_doubleget_floatget_intget_longget_string
For printf, too, there are different placeholders for each type:
%cfor chars%ffor floats, doubles%ifor ints%lifor longs%sfor strings
And there are some mathematical operators we can use:
+for addition-for subtraction*for multiplication/for division%for remainder
More examples
1 |
|
- We declared a new function with
void cough(void);, before ourmainfunction calls it. The C compiler reads our code from top to bottom, so we need to tell it that thecoughfunction exists, before we use it. Then, after ourmainfunction, we can implement thecoughfunction. This way, the compiler knows the function exists, and we can keep ourmainfunction close to the top.
We can abstract cough further:
1 |
|
Let’s look at positive.c:
1 |
|
- The CS50 library doesn’t have a
get_positive_intfunction, but we can write one ourselves. Our functionint get_positive_int(void)will prompt the user for anintand return thatint, which our main function stores asi. Inget_positive_int, we initialize a variable,int n, without assigning a value to it yet. Then, we have a new construct,do ... while, which does something first, then checks a condition, and repeats until the condition is no longer true. - Once the loop ends because we have an n that is not < 1, we can return it with the return keyword. And back in our
mainfunction, we can setint ito that value.
Memory, imprecision, and overflow
Our computer has memory, in hardware chips called RAM, random-access memory. Our programs use that RAM to store data as they run, but that memory is finite. So with a finite number of bits, we can’t represent all possible numbers (of which there are an infinite number of). So our computer has a certain number of bits for each float and int, and has to round to the nearest decimal value at a certain point.
With floats.c, we can see what happens when we use floats:
1 |
|
- With
%50f, we can specify the number of decimal places displayed. Hmm, now we get …
1
2
3x: 1
y: 10
x / y = 0.10000000149011611938476562500000000000000000000000It turns out that this is called floating-point imprecision, where we don’t have enough bits to store all possible values, so the computer has to store the closest value it can to 1 divided by 10.
Problem Set 1
Week 2 Arrays
resource
Compiling
If we wanted to use CS50’s library, via #include <cs50.h>, for strings and the get_string function, we also have to add a flag: clang -o hello hello.c -lcs50. The -l flag links the cs50 file, which is already installed in the CS50 Sandbox, and includes prototypes, or definitions of strings and get_string (among more) that our program can then refer to and use.
We write our source code in C, but need to compile it to machine code, in binary, before our computers can run it.
clangis the compiler, andmakeis a utility that helps us runclangwithout having to indicate all the options manually.
『Compiling』 source code into machine code is actually made up of smaller steps:
- preprocessing
- compiling
- assembling
- linking
Preprocessing
Preprocessing involves looking at lines that start with a #, like #include, before everything else. For example, #include <cs50.h> will tell clang to look for that header file first, since it contains content that we want to include in our program. Then, clang will essentially replace the contents of those header files into our program.
- For example
1 |
|
will be preprocessed into:
1 | string get_string(string prompt); |
Compiling
Compiling takes our source code, in C, and converts it to assembly code, which looks like this:
1 | ... |
These instructions are lower-level and is closer to the binary instructions that a computer’s CPU can directly understand. They generally operate on bytes themselves, as opposed to abstractions like variable names.
assembling
The next step is to take the assembly code and translate it to instructions in binary by assembling it. The instructions in binary are called machine code, which a computer’s CPU can run directly.
linking
The last step is linking, where the contents of previously compiled libraries that we want to link, like cs50.c, are actually combined with the binary of our program. So we end up with one binary file, a.out or hello, that is the compiled version of hello.c, cs50.c, and printf.c.
Debugging
Bugs are mistakes in programs that we didn’t intend to make. And debugging is the process of finding and fixing bugs.
Data Types
In C, we have different types of variables we can use for storing data:
- bool 1 byte
- char 1 byte
- int 4 bytes
- float 4 bytes
- long 8 bytes
- double 8 bytes
- string ? bytes
Each of these types take up a certain number of bytes per variable we create, and the sizes above are what the sandbox, IDE, and most likely your computer uses for each type in C.
Memory
Inside our computers, we have chips called RAM, random-access memory, that stores data for short-term use. We might save a program or file to our hard drive (or SSD) for long-term storage, but when we open it, it gets copied to RAM first. Though RAM is much smaller, and temporary (until the power is turned off), it is much faster.
We can think of bytes, stored in RAM, as though they were in a grid:
- In reality, there are millions or billions of bytes per chip.
In C, when we create a variable of type char, which will be sized one byte, it will physically be stored in one of those boxes in RAM. An integer, with 4 bytes, will take up four of those boxes.
And each of these boxes is labeled with some number, or address, from 0, to 1, to 2, and so on.
Functions
Function Declarations
1 | return-type name (argument-list) |
- The
return-typeis what kind of variable the function will output. - The
nameis what you want to call your function. - The
argument-listis the common-separated set of inputs to your function, each of which has a type and a name.
1 | int add_two_ints(int a, int b); |
Variable Scope
Scope is a characteristic of a variable that defines from which functions that variable may be accessed
- Local variable can only be accessed within the functions in which they are created.
- Global variables can be accessed by any function in the program.
For the most part, local variables in C are passed by value in function calls.
Arrays
In memory, we can store variables one after another, back-to-back. And in C, a list of variables stored, one after another in a contiguous chunk of memory, is called an array.
For example, we can use int scores[3]; to declare an array of 3 integers.
And we can assign and use variables in an array with:
1 |
|
- We can use the
constkeyword to tell the compiler that the value ofNshould never be changed by our program.
In memory, our array is now stored like this, where each value takes up not one but four bytes:

- Arrays are a fundamental data structure, and they are extremely useful!
- We use arrays to hold values of the same type at contiguous memory locations.
- One way to analogize the notion of array is to think of your local post office, which usually has a large bank of post office boxes.
Array declarations
1 | type name[size] |
- The type is what kind of variable each element of the array will be.
- The name is what you want to call your array.
- The size is how many elements you would like your array to contain.
initial value
1 | // instantiation syntax |
multi dimension array
1 | bool battleship[10][10] |
notes
- While we can treat individual elements of arrays as variables, we cannot treat entire arrays themselves as variables.
- We cannot, for instance, assign one array to another using the assignment operator. That is not legal C.
Instead, we must use a loop to copy over the elements one at a time.
Recall that most variables in C are passed by value in function calls.
- Arrays do not follow this rule. Rather, they are passed by reference. The callee reveives the actual array, not a copy of it.
Strings
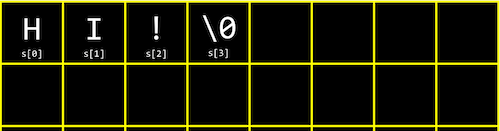
Strings are actually just arrays of characters. If we had a string s, each character can be accessed with s[0], s[1], and so on.
And it turns out that a string ends with a special character, \0, or a byte with all bits set to 0. This character is called the null character, or null terminating character. So we actually need four bytes to store our string 『HI!』:
Now let’s see what four strings in an array might look like:
1 | string names[4]; |
We can visualize each character with its own label in memory:

Command-line arguments
Programs of our own can also take in command-line arguments.
We change what our main function looks like:
1 |
|
argc and argv are two variables that our main function will now get, when our program is run from the command line. argc is the argument count, or number of arguments, and argv is an array of strings that are the arguments. And the first argument, argv[0], is the name of our program (the first word typed, like ./hello). In this example, we check if we have two arguments, and print out the second one if so.
It turns out that we can indicate errors in our program by returning a value from our main function (as implied by the int before our main function). By default, our main function returns 0 to indicate nothing went wrong, but we can write a program to return a different value:
1 |
|
Readability
Now that we know how to work with strings in our programs, we can analyze paragraphs of text for their level of readability, based on factors like how long and complicated the words and sentences are.
Encryption
If we wanted to send a message to someone, we might want to encrypt, or somehow scramble that message so that it would be hard for others to read. The original message, or input to our algorithm, is called plaintext, and the encrypted message, or output, is called ciphertext.
An encryption algorithm generally requires another input, in addition to the plaintext. A key is needed, and sometimes it is simply a number, that is kept secret. With the key, plaintext can be converted, via some algorith, to ciphertext, and vice versa.
For example, if we wanted to send a message like I L O V E Y O U, we can first convert it to ASCII: 73 76 79 86 69 89 79 85. Then, we can encrypt it with a key of just 1 and a simple algorithm, where we just add the key to each value: 74 77 80 87 70 90 80 86. Then, someone converting that ASCII back to text will see J M P W F Z P V. To decrypt this, someone will need to know the key.
Problem Set 2
Week 3 Algorithms
resource
Week 3 - CS50x
Lecture 3 - CS50x
Searching
linear search
In linear search, the idea of the algorithm is to iterate across the array from left to right, searching for a specified element.
binary search
Start in the middle and move left or right depending on what we’re looking for, if our array of items is sorted.
Big O
Big O is the upper bound of number of steps, or the worst case, and typically what we care about more.
Computer scientists might also use big Ω, big Omega notation, which is the lower bound of number of steps for our algorithm.
Structs
It turns out that we can make our own custom data types called structs:
1 |
|
We can think of structs as containers, inside of which are multiple other data types.
Sorting
Recursion
Recursion occurs when a function or algorithm refers to itself.
Merge sort
We can take the idea of recusion to sorting, with another algorithm called merge sort. The pseudocode might look like:1
2
3
4
5
6If only one item
Return
Else
Sort left half of items
Sort right half of items
Merge sorted halves
Algorithms Summary
Problem Set 3
Week 4 Memory
resource
Week 4 - CS50x
Lecture 4 - CS50x
Hexadecimal
The addresses for memory use the counting system hexadecimal, where there are 16 digits, 0-9 and A-F.
In writing, we can indicate a value is in hexadecimal by prefixing it with 0x, as in 0x10, where the value is equal to 16 in decimal, as opposed to 10.
Pointers
Pointer provide an alternative way to pass data between functions.
- recall that up to this point, we have passed all data by value, with one exception.
- when we pass data by value, we only pass a copy of that data.
If we use pointer instead, we have the power to pass the actual variable itself.
- that means that a change that is made in one function can impact what happens in a different function.
- previously, this wasn’t possible.
Recall from our discussion of arrays that they not only are useful for storage of information but also for so-called random access
- we can access individual elements of the array by indicating which index location we want.
Similarly, each location in memory has a address.
A pointer, then, is a data item whose
- value is a memory address
- type describes the data located at that memory address
Pointer make a computer enviroment more like the real world.
NULL pointer
The simplest pointer available is the NULL pointer.
- As you might expect, this pointer points to nothing(a fact which can actually come in handy!)
When you create a pointer and you don’t set its value immediately, you should always set the value of the pointer to NULL.
You can check whether a pointer is NULL using the quality operator(==).
&
Another easy way to create a pointer is to simply extract the address of an already existing variable. We can do this with the address extraction operator(&).
If x is an int-type variable, the &x is a pointer-to-int whose value is the address of x.
If arr is an array of doubles, the &add[i] is a pointer-to-double who value is the address of the ith element of arr.
- An array’s name, then, is actually just a pointer to its first element you’ve been working with pointers all along!
*
Using in this context, * is known as the dereference operator.
It “goes to the reference” and accesses the data at that memory location, allowing you to manipulate it at will.
This is just like visiting your neighbor. Having their address isn’t enough. You need to go to the address and only then can you interact with them.
Segmentation fault
Can you guess what might happen if we try to dereference a pointer whose value is NULL?
- Segmentation fault
Surprisingly, this is actually good behavior! It defends against accidental dangerous manipulation of unknown pointers.
- That’s why we recommend you set your pointers to NULL immediately if you aren’t setting them to a known, desired value.
int* p;
- The value of
pis an address. - We can dereference
pwith the*operator. - If we do, what we’ll find at that location is an int.
We might create a value n, and print it out:
1 |
|
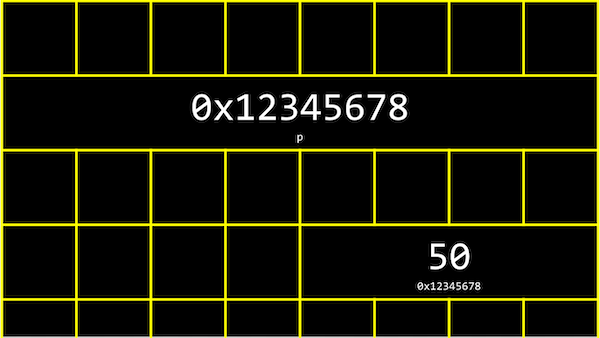
In our computer’s memory, there are now 4 bytes somewhere that have the binary value of 50, labeled n:

It turns out that, with the billions of bytes in memory, those bytes for the variable n starts at some unique address that might look like 0x12345678.
In C, we can actually see the address with the & operator, which means 『get the address of this variable』:
1 |
|
we might see an address like 0x7ffe00b3adbc, where this is a specific location in the server’s memory.
The address of a variable is called a pointer, which we can think of as a value that 『points』 to a location in memory. The * operator lets us 『go to』 the location that a pointer is pointing to.
For example, we can print *&n, where we 『go to』 the address of n, and that will print out the value of n, 50, since that’s the value at the address of n:
1 |
|
We also have to use the * operator (in an unfortunately confusing way) to declare a variable that we want to be a pointer:
1 |
|
- Here, we use int
*pto declare a variable,p, that has the type of*, a pointer, to a value of typeint, an integer. Then, we can print its value (something like0x12345678), or print the value at its location withprintf("%i\n", *p);.
In our computer’s memory, the variables might look like this:
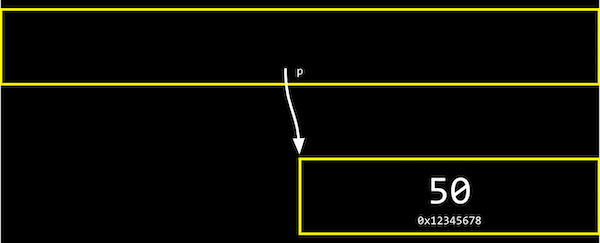
We have a pointer, p, with the address of some variable.
We can abstract away the actual value of the addresses now, since they’ll be different as we declare variables in our programs, and simply think of p as 『pointing at』 some value:
Many modern computer systems are 『64-bit』, meaning that they use 64 bits to address memory, so a pointer will be 8 bytes, twice as big as an integer of 4 bytes.
string
It turns out that each character is stored in memory at a byte with some address, and s is actually just a pointer with the address of the first character:
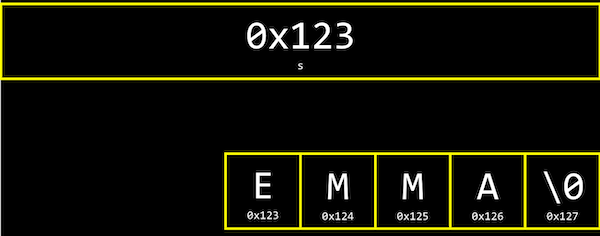
And since s is just a pointer to the beginning, only the \0 indicates the end of the string.
In fact, the CS50 Library defines a string with typedef char *string, which just says that we want to name a new type, string, as a char *, or a pointer to a character.
we can just say:
1 |
|
- With
printf("%p\n", s);, we can printsas its value as a pointer, like0x42ab52. (printfknows to go to the address and print the entire string when we use%sand pass ins, even thoughsonly points to the first character.) - We can also try
printf("%p\n", &s[0]);, which is the address of the first character ofs, and it’s exactly the same as printings. And printing&s[1],&s[2], and&s[3]gets us the addresses that are the next characters in memory after&s[0], like0x42ab53,0x42ab54, and0x42ab55, exactly one byte after another. - And finally, if we try to
printf("%c\n", *s);, we get a single characterE, since we’re going to the address contained ins, which has the first character in the string. - In fact,
s[0],s[1], ands[2]actually map directly to*s,*(s+1), and*(s+2), since each of the next characters are just at the address of the next byte.
Compare and copy
1 |
|
We see that the same string values are causing our program to print 『Different』.
Given what we now know about strings, this makes sense because each 『string』 variable is pointing to a different location in memory, where the first character of each string is stored. So even if the values of the strings are the same, this will always print 『Different』.
Now let’s try to copy a string:
1 |
|
- when we run our program, we see that both
sandtare now capitalized. - Since we set
sandtto the same values, they’re actually pointers to the same character, and so we capitalized the same character!
To actually make a copy of a string, we have to do a little more work:
1 |
|
- We create a new variable,
t, of the typechar *, withchar *t. Now, we want to point it to a new chunk of memory that’s large enough to store the copy of the string. Withmalloc, we can allocate some number of bytes in memory (that aren’t already used to store other values), and we pass in the number of bytes we’d like. We already know the length ofs, so we add 1 to that for the terminating null character. So, our final line of code ischar *t = malloc(strlen(s) + 1);. - Then, we copy each character, one at a time, and now we can capitalize just the first letter of
t. And we usei < n + 1, since we actually want to go up ton, to ensure we copy the terminating character in the string. - We can actually also use the
strcpylibrary function withstrcpy(t, s)instead of our loop, to copy the stringsintot. To be clear, the concept of a 『string』 is from the C language and well-supported; the only training wheels from CS50 are the type string instead ofchar *, and theget_stringfunction.
If we didn’t copy the null terminating character, \0, and tried to print out our string t, printf will continue and print out the unknown, or garbage, values that we have in memory, until it happens to reach a \0, or crashes entirely, since our program might end up trying to read memory that doesn’t belong to it!
valgrind
After we’re done with memory that we’ve allocated with malloc, we should call free (as in free(t)), which tells our computer that those bytes are no longer useful to our program, so those bytes in memory can be reused again.
If we kept running our program and allocating memory with malloc, but never freed the memory after we were done using it, we would have a memory leak, which will slow down our computer and use up more and more memory until our computer runs out.
valgrind is a command-line tool that we can use to run our program and see if it has any memory leaks. We can run valgrind on our program above with help50 valgrind ./copy and see, from the error message, that line 10, we allocated memory that we never freed (or 『lost』).
buffer overflow,
Let’s take a look at memory.c:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// http://valgrind.org/docs/manual/quick-start.html#quick-start.prepare
void f(void)
{
int *x = malloc(10 * sizeof(int));
x[10] = 0;
}
int main(void)
{
f();
return 0;
}
- This is an example from valgrind’s documentation (valgrind is a real tool, while help50 was written specifically to help us in this course).
- The function
fallocates enough memory for 10 integers, and stores the address in a pointer calledx. Then we try to set the 11th value ofxwithx[10]to0, which goes past the array of memory we’ve allocated for our program. This is called buffer overflow, where we go past the boundaries of our buffer, or array, and into unknown memory.
Swap
Let’s say we wanted to swap the values of two integers.
1 | void swap(int a, int b) |
If we tried to use that function in a program, we don’t see any changes:
1 |
|
It turns out that the swap function gets its own variables, a and b when they are passed in, that are copies of x and y, and so changing those values don’t change x and y in the main function.
Memory layout
Within our computer’s memory, the different types of data that need to be stored for our program are organized into different sections:

- The machine code section is our compiled program’s binary code. When we run our program, that code is loaded into the 『top』 of memory.
- Globals are global variables we declare in our program or other shared variables that our entire program can access.
- The heap section is an empty area where
malloccan get free memory from, for our program to use. - The stack section is used by functions in our program as they are called. For example, our
mainfunction is at the very bottom of the stack, and has the local variablesxandy. Theswapfunction, when it’s called, has its own frame, or slice, of memory that’s on top ofmain’s, with the local variablesa,b, andtmp:

- Once the function
swapreturns, the memory it was using is freed for the next function call, and we lose anything we did, other than the return values, and our program goes back to the function that calledswap. - So by passing in the addresses of
xandyfrommaintoswap, we can actually change the values ofxandy:

- By passing in the address of
xandy, ourswapfunction can actually work:
1 |
|
The addresses of
xandyare passed in frommaintoswap, and we use theint *asyntax to declare that ourswapfunction takes in pointers. We save the value ofxtotmpby following the pointera, and then take the value ofyby following the pointerb, and store that to the locationais pointing to (x). Finally, we store the value oftmpto the location pointed to byb(y), and we’re done.If we call
malloctoo many times, we will have a heap overflow, where we end up going past our heap. Or, if we have too many functions being called, we will have a stack overflow, where our stack has too many frames of memory allocated as well. And these two types of overflow are generally known as buffer overflows, after which our program (or entire computer) might crash.
Dynamic Memory Allocation
Dynamic Memory Allocation - YouTube
We’ve seen one way to work with pointer, naming pointing a pointer variable at another variable that already exists in our system.
- This requires us to know exactly how much memory our system will need at the moment out program is compiled.
What if we don’t know how much memory we’ll need at compile-time? How do we get access to new memory while out program is running.
heap
We can use pointers to get access to block of dynamically-allocated memory at runtime.
Dynamically allocated memory comes from a pool of memory known as the heap.
Prior to this point, all memory we’ve been working with has been coming from a pool of memory known as the stack.
We get this dynamic-allocated memory by making a call to the C standard library function malloc(), passing as its parameter the number of bytes requested.
After obtaining memory for you (if it can), malloc() will return a pointer to that memory.
What if malloc() can’t give you memory? It’ll hand you back NULL.
dynamically obtain an integer
1 | // statically obtain an integer |
another
1 | // get an integer from the user |
attention
Here’s the trouble: Dynamic-allocated memory is not automatically returned to the system for later use when the function in which it’s created finishes execution.
Failing to return memory back to the system when you’re finished with it results in a memory leak which can compromise your system’s performance.
When you finish working with dynamically-allocated memory, you must free() it.
Three golden rules:
- Every block of memory that you
malloc()must subsequently befree()d. - Only memory that you
malloc()should befree()d. - Do not
free()a block of memory more than once.
Call Stacks
When you call a function, the system sets aside space in memory for that function to do its necessary work.
- We frequently call such chunks of memory stack frames or function frames.
- More than one function’s stack frame may exist in memory at a given time. If
main()callsmove(), which then callsdirection(), all three functions have open frames.
These frames are arranged in a stack. The frame for the most-recently called function is always on the top of the stack.
When a new function is called, a new frame is pushed onto the top of the stack and becomes the active frame.
When a function finishes its work, its frame is popped off of the stack, and the frame immediately below it becomes the new, active, function on the top of the stack. This function picks up immediately where it left off.
File Pointers
The ability to read data from and write data to files is the primary means of storing persistent data, data that does not disappear when your program stops running.
The abstraction of files that C provides is implemented in a data structure known as a FILE.
- Almost universally when working with files, we will be using pointers to them,
FILE*.
The file manipulation functions all live in stdio.h.
- All of them accept
FILE*as one of their parameters, except for the functionfopen(), which is used to get a file pointer in the first place.
Some of the most common file input/ouput(I/O) functions that we’ll be working with are:
fopen()fclose()fgetc()fputc()fread()fwrite()
fopen()
- open a file and returns a file pointer to it.
- Always check the return value to make sure you don’t get back NULL.
1 | FILE* ptr = fopen(<filenema>, <operation>); |
- operation: read
r, writew, appenda
fclose()
- close the file pointed to by the given file pointer
1 | fclose(<file pointer>); |
fgetc()
- reads and returns the next character from the file pointed to.
- note: the operation of the file pointer passed in as a parameter must be
rfor read, or you will suffer an error.
1 | char ch = fgetc(<file pointer>); |
- The ability to get single character from file, if wrapped in a loop, means we could read all the characters from a file and print them to the screen, one-by-one, essentially.
1 | char ch; |
- we might put this in a file called
cat.cafter the linux command “cat” which essentially does just this.
fputc()
- writes or appends the specified character to the pointed-to file.
- note: the operation of the file pointer passed in as parameter must be
wfor write orafor append, or you will suffer an error.
Now we can read characters from files and write characters to them. Let’s extend our previous example to copy one file to another, instead of printing to the screen.
1 | char ch |
- we might put this in a file called
cp.c, after the Linux command “cp” which essentially does just this.
fread()
- reads
<qty>units of<size>from the file pointed to and stores them in memory in a buffer(usually an array) pointed to by<buffer>. - note: the operation of the file pointer passed in as a parameter must by
rfor read, or you will suffer an error.
1 | fread(<buffer>, <size>, <qty>, <file pointer>); |
example:
1 | int arr[10]; |
1 | double* arr2 = malloc(sizeof(double) * 80); |
make it act like fputc():
1 | char c; |
fwrite()
- writes
<qty>units of size<size>to the file pointed to by reading them from a buffer(usually an array) pointed to by<buffer>. - note: the operation of the file pointer passed in as a paramater must be
wfor write orafor append, or you will suffer an error.
1 | fwrite(<buffer>, <size>, <qty>, <file pointer>); |
additional
fgets(): reads a full string from a file.fputs(): writes a full string to a file.fprintf(): writes a formatted string to a file.fseek(): allows you to rewind or fast-forward within a file.ftell(): tells you at what(byte) position you are at within a file.feof(): tells you whether you’ve read to the end of a file.ferror(): indicates whether an error has occurred in working with a file.
get_int
We can implement get_int ourselves with a C library function, scanf:
1 |
|
scanftakes a format,%i, so the input is 『scanned』 for that format, and the address in memory where we want that input to go. Butscanfdoesn’t have much error checking, so we might not get an integer.
We can try to get a string the same way:
1 |
|
- But we haven’t actually allocated any memory for
s(sisNULL, or not pointing to anything), so we might want to callchar s[5]to allocate an array of 5 characters for our string. Then,swill be treated as a pointer inscanfandprintf. - Now, if the user types in a string of length 4 or less, our program will work safely. But if the user types in a longer string,
scanfmight be trying to write past the end of our array into unknown memory, causing our program to crash.
Files
1 |
|
fopenis a new function we can use to open a file. It will return a pointer to a new type,FILE, that we can read from and write to. The first argument is the name of the file, and the second argument is the mode we want to open the file in (rfor read,wfor write, andafor append, or adding to).- After we get some strings, we can use
fprintfto print to a file. - Finally, we close the file with
fclose.
Now we can create our own CSV files, files of comma-separated values (like a mini-spreadsheet), programmatically.
JPEG
We can also write a program that opens a file and tells us if it’s a JPEG (image) file:
1 |
|
- Now, if we run this program with
./jpeg brian.jpg, our program will try to open the file we specify (checking that we indeed get a non-NULL file back), and read the first three bytes from the file withfread. - We can compare the first three bytes (in hexadecimal) to the three bytes required to begin a JPEG file. If they’re the same, then our file is likely to be a JPEG file (though, other types of files may still begin with those bytes). But if they’re not the same, we know it’s definitely not a JPEG file.
We can use these abilities to read and write files, in particular images, and modify them by changing the bytes in them.
Problem Set 4
Week 5 Data Structures
resource
Week 5 - CS50x
Lecture 5 - CS50x
Problem Set 5 - CS50x
Pointers
1 | int main(void) |
- Here, the first two lines of code in our
mainfunction are declaring two pointers,xandy. Then, we allocate enough memory for anintwithmalloc, and stores the address returned bymallocintox. - With
*x = 42;, we go to the address pointed to byx, and stores the value42into that location. The final line, though, is buggy since we don’t know what the value of
yis, since we never set a value for it. Instead, we can write:1
2y = x;
*y = 13;- And this will set
yto point to the same location asxdoes, and then set that value to13.
- And this will set
Resizing arrays
- we need to declare the size of arrays when we create them, and when we want to increase the size of the array, the memory surrounding it might be taken up by some other data.
- One solution might be to allocate more memory in a larger area that’s free, and move our array there, where it has more space. But we’ll need to copy our array, which becomes an operation with running time of O(n), since we need to copy each of n elements in an array.
1 |
|
- It turns out that there’s actually a helpful function,
realloc, which will reallocate some memory:
1 |
|
Data structures
- Data structures are programming constructs that allow us to store information in different layouts in our computer’s memory.
- To build a data structure, we’ll need some tools we’ve seen:
structto create custom data types.to access properties in a structure*to go to an address in memory pointed to by a pointer
Linked Lists
1 | typedef struct node |
We start this struct with typedef struct node so that we can refer to a node inside our struct.
To add an element, first we’ll need to allocate some memory for a node, and set its values:
1 | node *n = malloc(sizeof(node)); |
delete an entire linked list
1 | void destroy(sllnode* head); |
step involved:
a. if you’ve reached a null pointer, stop
b. delete the rest of the list(recursion)
c. free the current node
doubly-linked lists
singly-linked lists really extend our ability to collect and organize data, but they suffer from a crucial limitation
- ww can only ever move in one direction through the list
A doubly-linked list, by contrast, allow us to move forward and backward through the list, all by simply adding one extra pointer to our struct definition.
insert
1 | dllnode* insert(dllnode* head, VALUE val); |
steps involved:
a. dynamically allocate space for a new dllnode
b. check to make sure we didn’t run out of memory
c. populate and insert the node at the beginning of the linked list
d. fix the prev pointer of the old head of the linked list
e. return a pointer to the new head of the linked list
hash table
hash table combine the random access ability of an array with the dynamism of a linked list.
we’re gaining the advantages of both types of data structure, while mitigating the disadvantages.
good hash function
a good hash function should
- use only the data being hashed
- use all of the data being hashed
- be deterministic
- uniformly distribute data
- generate very different hash codes for very similar data
1 | unsigned int hash(char* str) |
collision
a collision occurs when two pieces of data, when run through the hash function, yield the same hash code.
resolving collisions: linear probing
in this method, if we have a collision, we try to place the data in the next consecutive element in the array(wrapping around to the begining if necessary) until we find a vacancy.
that way, if we don’t find what we’re looking for in the first location, at least hopefully the element is somewhere nearby.
resolving collisions: chaning
what if instead of each element of the array holding just one piece of data, it held multiple pieces of data?
if each element of the array is a pointer to the head of a linked list, then multiple pieces of data can yield the same hash code and we’ll be able to store it all!
tries
what about a slightly different kind of data structure where the key is guaranteed to be unique, and the value could be as simple as a Boolean that tells you whether the data exists in the structure?
tries combine structure and pointers together to store data in an interesting way.
the data to be searched for in the trie is now a roadmap.
- if you can follow the map from beginning to end, the data exists in the trie.
- if you can’t, it doesn’t
unlike with a hash table, there are no collisions, and no two pieces of data(unless they are identical) have the same path.
insert
to insert an element into the trie, simply build the correct path from the root of the leaf.
1 | typedef struct _trie |
search
to search for an element in the trie, use successive digits to navigate from the root, and if you can make it to the end without hitting a dead end(a NULL pointer), you’ve found it.
More data structures
tree
A tree is another data structure where each node points to two other nodes, one to the left (with a smaller value) and one to the right (with a larger value)
Now, we can easily do binary search, and since each node is pointing to another, we can also insert nodes into the tree without moving all of them around as we would have to in an array. Recursively searching this tree would look something like:
1 | typedef struct node |
hash table
A data structure with almost a constant time search is a hash table, which is a combination of an array and a linked list. We have an array of linked lists, and each linked list in the array has elements of a certain category. For example, in the real world we might have lots of nametags, and we might sort them into 26 buckets, one labeled with each letter of the alphabet, so we can find nametags by looking in just one bucket.
trie
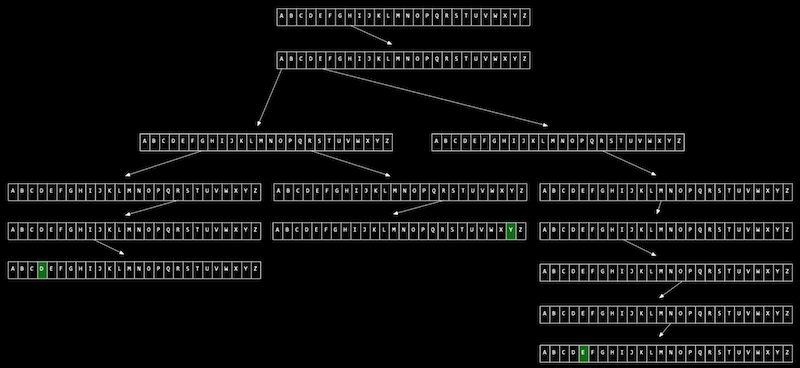
Imagine we want to store a dictionary of words efficiently, and be able to access each one in constant time.
A trie is like a tree, but each node is an array. Each array will have each letter, A-Z, stored. For each word, the first letter will point to an array, where the next valid letter will point to another array, and so on, until we reach something indicating the end of a valid word. If our word isn’t in the trie, then one of the arrays won’t have a pointer or terminating character for our word. Now, even if our data structure has lots of words, the lookup time will be just the length of the word we’re looking for, and this might be a fixed maximum so we have O(1) for searching and insertion. The cost for this, though, is 26 times as much memory as we need for each character.
data structures summary
arrays
- insertion is bad - lots of shifting to fit an element in the middle
- deletion is bad - lots of shifting after removing an element
- lookup is great - random access, constant time
- relatively easy to sort
- relatively easy small size-wise
- stuck with fixed size, no flexibility
linked lists
- insertion is easy - just tack onto the front
- deletion is easy - once you find the element
- lookup is bad - have to rely on linear search
- reletively difficult to sort - unless you’re willing to compromise on super-fast insertion and instead sort as you construct
- relatively small size-wise(not as small as arrays)
hash tables
- insertion is a two-step process - hash, then add
- deletion is easy - once you find the element
- lookup is on average better than with linked lists because you have the benifit of a real-world constant factor
- not an ideal data structure if sorting is the goal - just use an array
- can run the gamut of size
trie
- insertion is complex - a lot of dynamic memory allocation, but gets easier as you go
- deletion is easy - just free a node
- lookup is fast - not quite as fast as an array, but almost
- already sorted - sorts as you build in almost all situations
- rapidly becomes huge, even with very little data present, not great if space is at a premium
Week 6 Python 🐍
resource
Week 6 - CS50x
Lecture 6 - CS50x
Python Basics
1 | print("hello, world") |
Python is an interpreted language, which means that we actually run another program (an interpreter) that reads our source code and runs it top to bottom. For example, we can save the above as hello.py, and run the command python hello.py to run our code, without having to compile it.
conditionals
all of the old favorites from C are still available for you to use.
1 | letters_only = True if input().isalpha() else False |
loops
two varieties: while and for
1 | counter = 0 |
1 | for x in range(100): |
data types
In Python, there are many data types:bool, True or Falsefloat, real numbersint, integersstr, stringsrange, sequence of numberslist, sequence of mutable values, that we can change or add or removetuple, sequence of immutable values, that we can’t changedict, collection of key/value pairs, like a hash tableset, collection of unique values
tuples
tuples are ordered, immutable sets of data; they are great for associating collections of data, sort of like a struct in C, but where those values are unlikely to change.
Here is a list of tuples:
1 | presidents = [ |
This list is iterable as well:
1 | for prez, year in presidents: |
Dictionaries
python also has built in support for dictionaries, allowing you to specify list indices with words or phrases(keys), instead of integers, which you were restricted to in C.
1 | pizzaz = { |
iterate the dictionaries:
1 | for pie in pizzas: |
Object
Python is an object-oriented programming language.
An object is sort of analogous to a C structure.
Object, meanwhile, have properties but also methods, or functions that are inherent to the object, and mean nothing outside of it. You define the methods inside the object also.
- Thus, properties and methods don’t ever stand for their own.
You define a type of object using the class keyword in python.
Classes require an initialization function, also more-generally known as a constructor, which sets the starting values of the properties of the object.
In defining each method of an object, self should be its first parameter, which stipulates on what object the method is called.
1 | class Student(): |
1 | jane = Student("Jane", 10) |
Examples
blur an image
1 | from PIL import Image, ImageFilter |
dictionary
1 | words = set() |
iterate a string
1 | from cs50 import get_string |
More features
take command-line arguments
1 | from sys import argv |
Since argv is a list of strings, we can use len() to get its length, and range() for a range of values that we can use as an index for each element in the list.
But we can also let Python iterate over the list for us:
1 | from sys import argv |
We can return exit codes when our program exits, too:
1 | from sys import argv, exit |
linear search
1 | import sys |
dictionary
1 | import sys |
we declare dictionaries with curly braces, {}, and lists with brackets [].
Copying strings
1 | from cs50 import get_string |
Swapping two variables
1 | x = 1 |
Files
1 | import csv |
We can use the with keyword, which will helpfully close the file for us:
1 | ... |
New features
regular expressions
., for any character.*, for 0 or more characters.+, for 1 or more characters?, for something optional^, for start of input$, for end of input
Week 7 SQL
Often times, in order for us to build the most functional website we can, we depend on a database to store information.
Spreadsheets
A database is an application that can store data, and we can think of Google Sheets as one such application.
SQL
SQL(the Structured Query Language) is a programming language whose purpose is to query a database.
One other important consideration when constructing a table in SQL is to choose one column to be your primary key.
Primary keys enable rows of a table to be uniquely and quickly identified.
- Choosing your primary key appropriately can make subsequent operations on the table much easier.
It’s also possible to establish a joint primary key - a combination of two columns that is always guaranteed to be unique.
When defining the column that ultimately ends up being your table’s primary key, it’s usually a good idea to have that column be an integer.
Moreover, so as to eliminate the situation where you may accidentally forget to specify a real value for the primary key column, you can configure that column to autoincrement, so it will pre-populate that column for you automatically when rows are added to the table.
Operations
when working with data, we only need four operations:
CREATEREADUPDATEDELETE
In SQL, the commands to perform each of these operations are:
INSERTSELECTUPDATEDELETE
First, we’ll need to insert a table with the CREATE TABLE table (column type, ...); command.
insert
Add information to a table
1 | INSERT INTO |
select
extract information from a table.
1 | SELECT |
extract information from multiple tables.
1 | SELECT |
example
1 | SELECT |
update
modify information in a table
1 | UPDATE |
delete
remove information from a table.
1 | DELETE FROM |
datatype
BLOB, for “binary large object”, raw binary data that might represent filesINTEGERsmallintintegerbigint
NUMERICbooleandatedatetimenumeric(scale, precision), which solves floating-point imprecision by using as many bits as needed, for each digit before and after the decimal pointtimetimestamp
REALreal, for floating-point valuesdouble precision, with more bits
TEXTchar(n), for an exact number of charactersvarchar(n), for a variable number of characters, up to a certain limittext
calculations
After inserting values, we can use functions to perform calculations, too:
AVGCOUNTDISTINCT, for getting distinct values without duplicatesMAXMIN- …
There are also other operations we can combine as needed:
WHERE, matching on some strict conditionLIKE, matching on substrings for textLIMITGROUP BYORDER BYJOIN, combining data from multiple tables
update data
We can update data with UPDATE table SET column=value WHERE condition;, which could include 0, 1, or more rows depending on our condition. For example, we might say UPDATE favorites SET title = "The Office" WHERE title LIKE "%office", and that will set all the rows with the title containing “office” to be “The Office” so we can make them consistent.
And we can remove matching rows with DELETE FROM table WHERE condition;, as in DELETE FROM favorites WHERE title = "Friends";.
We can even delete an entire table altogether with another command, DROP.
IMDb
IMDb, or 『Internet Movie Database』, has datasets available to download as TSV, or tab-separate values, files.
For example, we can download title.basics.tsv.gz, which will contain basic data about titles:
tconst, a unique identifier for each title, likett4786824titleType, the type of the title, liketvSeriesprimaryTitle, the main title used, likeThe CrownstartYear, the year a title was released, like2016genres, a comma-separated list of genres, likeDrama,History
We’ll write import.py to read the file in:
1 | import csv |
We can write a program to search for a particular title:
1 | import csv |
In Python, we can connect to a SQL database and read our file into it once, so we can make lots of queries without writing new programs and without having to read the entire file each time.
1 | import cs50 |
Now we can run sqlite3 shows3.db and run commands like before, such as SELECT * FROM shows LIMIT 10;.
With SELECT COUNT(*) FROM shows; we can see that there are more than 150,000 shows in our table, and with SELECT COUNT(*) FROM shows WHERE startYear = 2019;, we see that there were more than 6000 this year.
Multiple tables
But each of the rows will only have one column for genres, and the values are multiple genres put together. So we can go back to our import program, and add another table:
1 | import cs50 |
- So now our
showstable no longer has a genres column, but instead we have agenrestable with each row representing a show and an associated genre. Now, a particular show can have multiple genres we can search for, and we can get other data about the show from theshowstable given its ID. - In fact, we can combine both tables with
SELECT * FROM shows WHERE id IN (SELECT show_id FROM genres WHERE genre = "Comedy") AND year = 2019;. We’re filtering our shows table by IDs where the ID in the genres table has a value of “Comedy” for thegenrecolumn, and has the value of 2019 for theyearcolumn. - Our tables look like this:
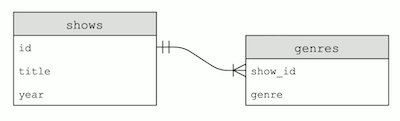
Since the ID in thegenretable come from theshowstable, we call itshow_id. And the arrow indicates that a single show ID might have many matching rows in thegenrestable.
By reading the descriptions for each table, we can see that all of the data can be used to construct these tables:
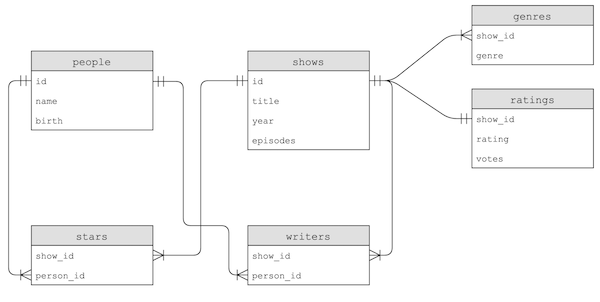
- Notice that, for example, a person’s name could also be copied to the
starsorwriterstables, but instead only theperson_idis used to link to the data in thepeopletable. This way, we only need to update the name in one place if we need to make a change.
We’ll download a program called DB Browser for SQLite), which will have a graphical user interface to browse our tables and data. We can use the 『Execute SQL』 tab to run SQL directly in the program, too.
We can run SELECT * FROM shows JOIN genres ON show.id = genres.show_id; to join two tables by matching IDs in columns we specify. Then we’ll get back a wider table, with columns from each of those two tables.
We can take a person’s ID and find them in shows with SELECT * FROM stars WHERE person_id = 1122;, but we can do a query inside our query with SELECT show_id FROM stars WHERE person_id = (SELECT id FROM people WHERE name = "Ellen DeGeneres");.
This gives us back the show_id, so to get the show data we can run: SELECT * FROM shows WHERE id IN (...); with … being the query above.
We can get the same results with:
1 | SELECT title FROM |
We join the people table with the stars table, and then with the shows table by specifying columns that should match between the tables, and then selecting just the title with a filter on the name.
But now we can select other fields from our combined tables, too.
It turns out that we can specify columns of our tables to be special types, such as:
PRIMARY KEY, used as the primary identifier for a rowFOREIGN KEY, which points to a row in another tableUNIQUE, which means it has to be unique in this tableINDEX, which asks our database to create a index to more quickly query based on this column. An index is a data structure like a tree, which helps us search for values.
We can create an index with CREATE INDEX person_index ON stars (person_id);. Then the person_id column will have an index called person_index. With the right indexes, our join query is several hundred times faster.
Problems
One problem with databases is race conditions, where the timing of two actions or events cause unexpected behavior.
To solve this, we can use transactions, where a set of actions is guaranteed to happen together.
Another problem in SQL is called a SQL injection attack, where an adversary can execute their own commands on our database.